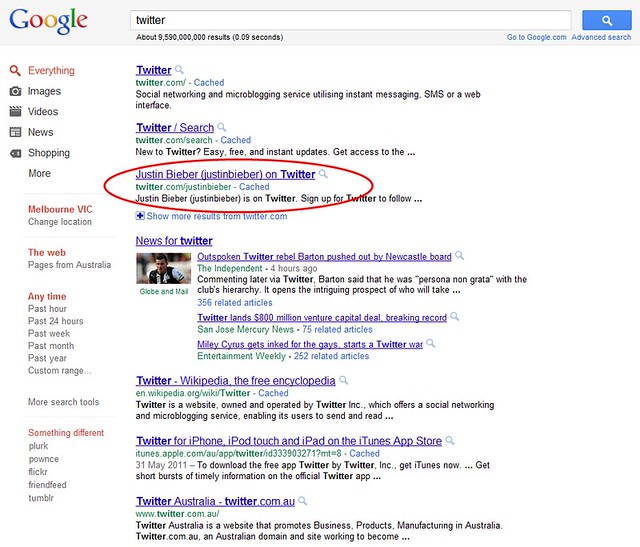
I’m someone who has made their escape from Twitter, mostly posting to a mix of Mastodon, Threads and Bluesky.
It was really easy to embed a Twitter post in WordPress: just paste the URL into the block editor and it’d do the hard work for you.
That doesn’t work for Mastodon, possibly because it’s so many different domains (servers) that WP can’t figure out when it’s a Mastodon post. Pasting the URL just displays… the URL.
Mastodon does have a function to get the embed code, which you can put into a WP Custom HTML block… but that didn’t work for me either. On my personal blog with its modified Twenty Twenty theme, the Mastodon post appeared hard against the left hand side of the browser window, out of whack with the rest of the post text.
With some experimentation and Googling, I discovered that tweaking the embed code slightly made it better.
Basically in the HTML, edit the blockquote style attribute margin and change it from 0 to auto. That made it appear in line with the rest of the post.
I’d love to show you it here, but it turns out the even older theme we’re using on geekrant.org.right now can’t handle them at all. Attempting to save a post with embedded Mastodon HTML results in a Save error. (And I don’t have time right now to get screen grabs.)
Hmm, might be time for a theme update.
Anyway, hope this helps someone else out there (and remind me of what I need to do next time).