
Brian Jones on why Microsoft Office 2000 (and later) produces such godawful HTML:
Our scenario was that people would start saving “docs†as HTML on their intranet sites and browse them with the browser. We viewed the browser as “electronic paper†that we had to “print†to (i.e. perfect fidelity). We had already got a lot of feedback from our Word97 Internet Assistant add-in that any loss of fidelity when saving as a web page was unacceptable and a “bugâ€. As it turned out, this usage scenario did not become as common as we thought it would and a zillion conspiracy theories formed about why we “really†did it. Many people assumed that a better approach would have been to save as “clean†HTML even if the result did not look exactly like what the user saw on the screen. We felt that the core office applications (other than FrontPage) were not really meant to be web page authoring tools, so we focused on converting docs to exact replicas in HTML. We didn’t want people losing any functionality when saving to HTML so we had to figure out a way to store everything that could have existed in a binary document as HTML. We thought we were clever creating a bunch of “mso-” css properties that allowed us to roundtrip everything. HTML didn’t take off in the same way we had expected, and today, the main use for Office HTML is for interoperability on the clipboard, though of course the biggest use is within e-mail (WordMail).
None of this explains why Office 2003’s “Filtered HTML” is so riddled with proprietary tags, though. Admittedly, a filtered HTML file is smaller than a roundtrip HTML file out of Word, but it’s still hugely bigger than the type of HTML you’d write from scratch (or in a web page editor such as Dreamweaver or Frontpage), and the source code is unreadable.
To my mind, Filtered HTML should be just that: HTML, filtered in such a way that the basic structure of the document is preserved, but none of the junk that Word (or whatever) stores along with it. Leave that for the roundtrip HTML — though I can’t see the appeal in that either, since if you want to store documents in a viewable form on the great InterWeb, PDF is the way to go. Or just store it in the native Office format for internal use, when you know every user will have the application or a viewer.
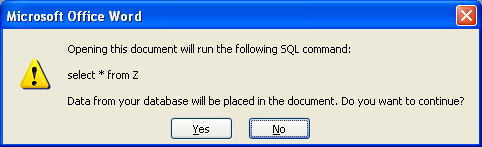 (By the way, when I was trying out the roundtrip HTML the other day, while reloading, Word presented me with a strange warning that it was going to query from some nonsense “Z” table to put data in the document. Bizarro. The test document did quote some SQL, but this would seem to suggest the roundtrip HTML isn’t all it’s cracked up to be.)
(By the way, when I was trying out the roundtrip HTML the other day, while reloading, Word presented me with a strange warning that it was going to query from some nonsense “Z” table to put data in the document. Bizarro. The test document did quote some SQL, but this would seem to suggest the roundtrip HTML isn’t all it’s cracked up to be.)
Anyway, Brian’s full article is about the progression of the Office formats from binary in the 90s into the XML to be used in the next version. Well worth a read if you want some background on the history, and where they’re going now.
I suspect there would be some organisations where you can’t expect everyone internally to have MS Office available internally as a viewer, due to cross platform reasons and the such. This was probably even more so in the past.
All this talk of XML, now if only they would support OpenDocument. All they’d have to do is support another schema, can’t be that hard for a company of their size. Obviously there are other motives though.
Hey- Linked over from the blogger.com. I have been working on a web
page as a complete newbie (not my normal work). Your blurb above explains
heaps as to why what I was writing and the output never matched up!
I have since abandoned trying to created a page using note pad or word.
Time to see what Dreamweaver has to offer.
I’ve discovered a good, freeware web editor: NVU.